Welcome to Modelor
Like many people, I’m experimenting with LLMs for sensemaking. These experiments include crude prototypes for tools. I thought it’d be fun to share the results and (hopefully) trace my progress, as it might help other folks.
I’m starting with a tool called LLMapper. Its purpose is to “read” web pages and draw a concept map that explains the page. Initially, sources are limited to Wikipedia. But that will change.
Currently, LLMapper is a simple bash script that uses Simon Willison’s llm, strip-tags, and ttok tools and Graphviz. It’s a crude prototype for the purpose of refining the prompts.
Here’s an example map generated for the Sengazhuneer Amman Temple page on Wikipedia:
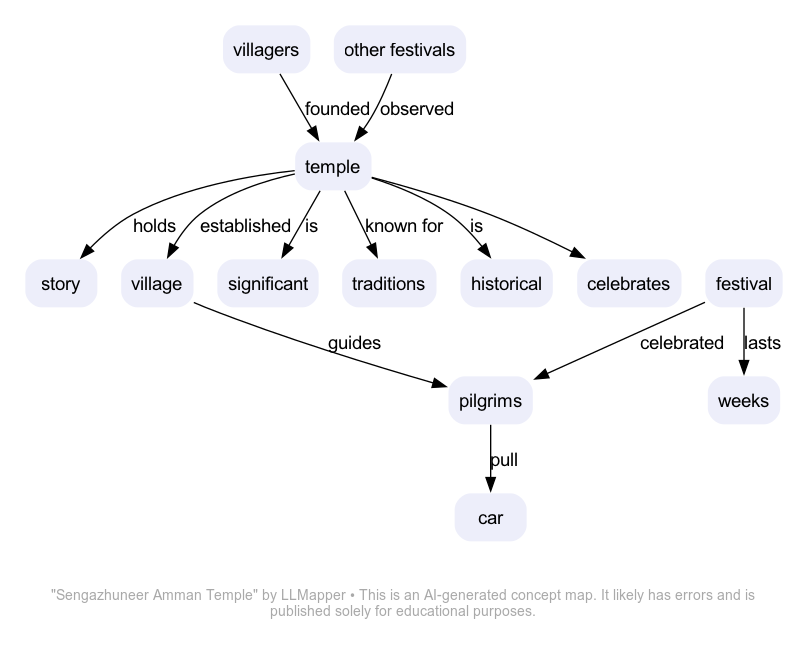
As you see, the map has lots of issues. But it’s about as good as what I see from many beginning students. This is still in ‘dancing bear’ terrain.
Shortcomings:
- It makes lots of stupid errors. (Not hallucinations – just bad form.)
- Truncating at 8,000 tokens limits what the script can see.
- Sometimes it produces ill-formed DOT.
Possible future improvements:
- Make it consistently generate good-enough maps. (This is my current focus.)
- Generalize it so it can read any public internet page.
- Add the ability to generate maps that answer user questions about the subject. (Currently, the question it answers is something like “What is [subject]?”)